To construct a Merkel Tree, we basically hash the individual data blocks and hash those hashes and hash those hashes and so on. Forming a tree structure.
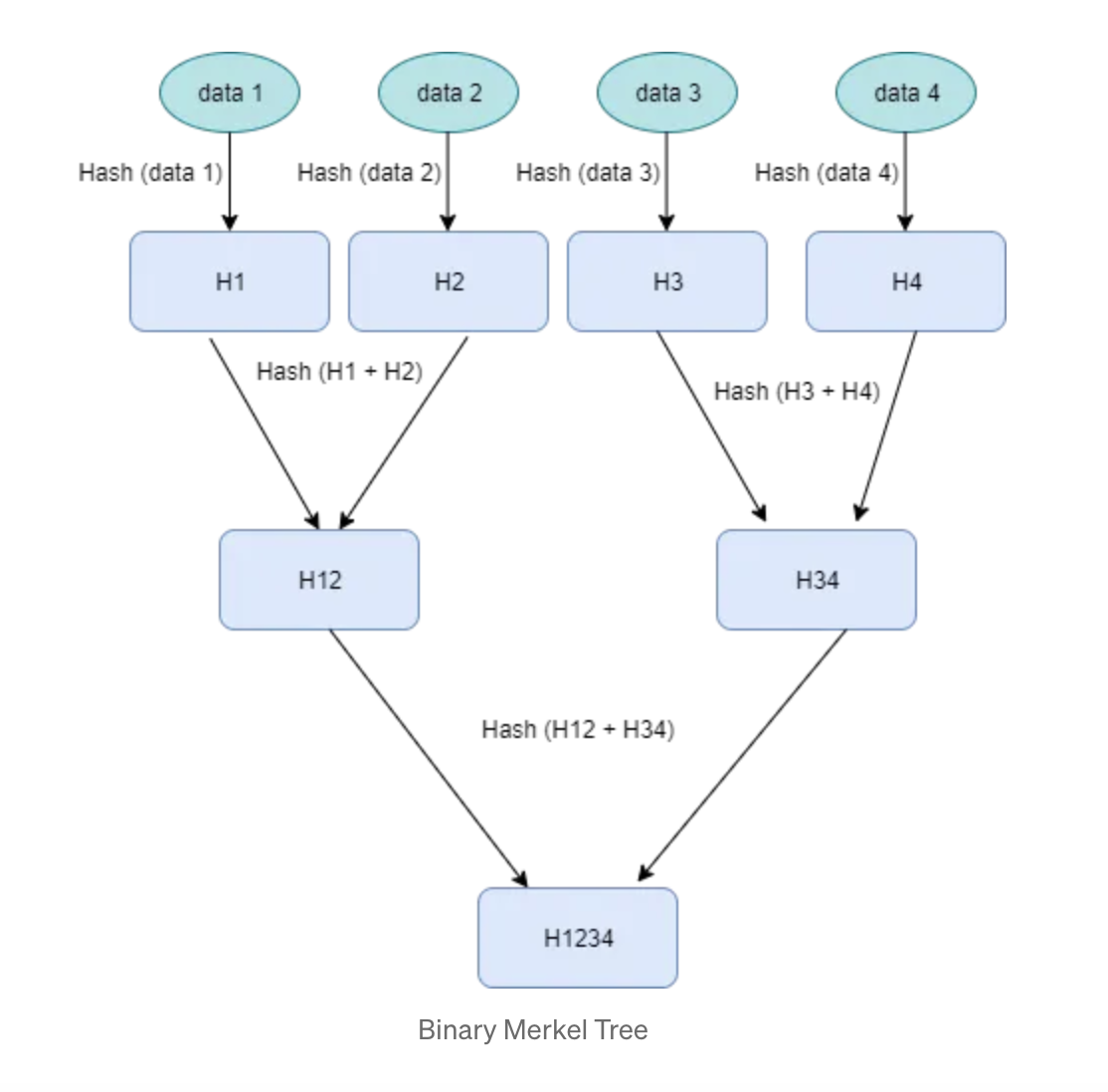
While hashing the hashes say H1, H2, H3 we append those hashes to get a single string H1 + H2 + H3 and hash that individual string to get a new hash H123.
Merkle Tree is mainly used to efficiently verify the integrity of the data.
Let’s take a closer look at the diagram above: hash H12 has basically the summary of data1 and data2. Even if a single bit in data1 or data2 changes it will be reflected in H12. Thus, if we are comparing two Merkle trees and found that H12 is the same in both. Then it guarantees that data1 and data2 haven’t been changed.
This way root of the tree holds the summary of all its children and we only need to compare the root node to detect the differences.
In order to identify the data nodes that have been changed. We can compare the root hashes. If that is different, we can compare the hashes of its children and so on.
Say, we were transferring the data from one server node to another. And in the meantime, data3 got updated in the source.
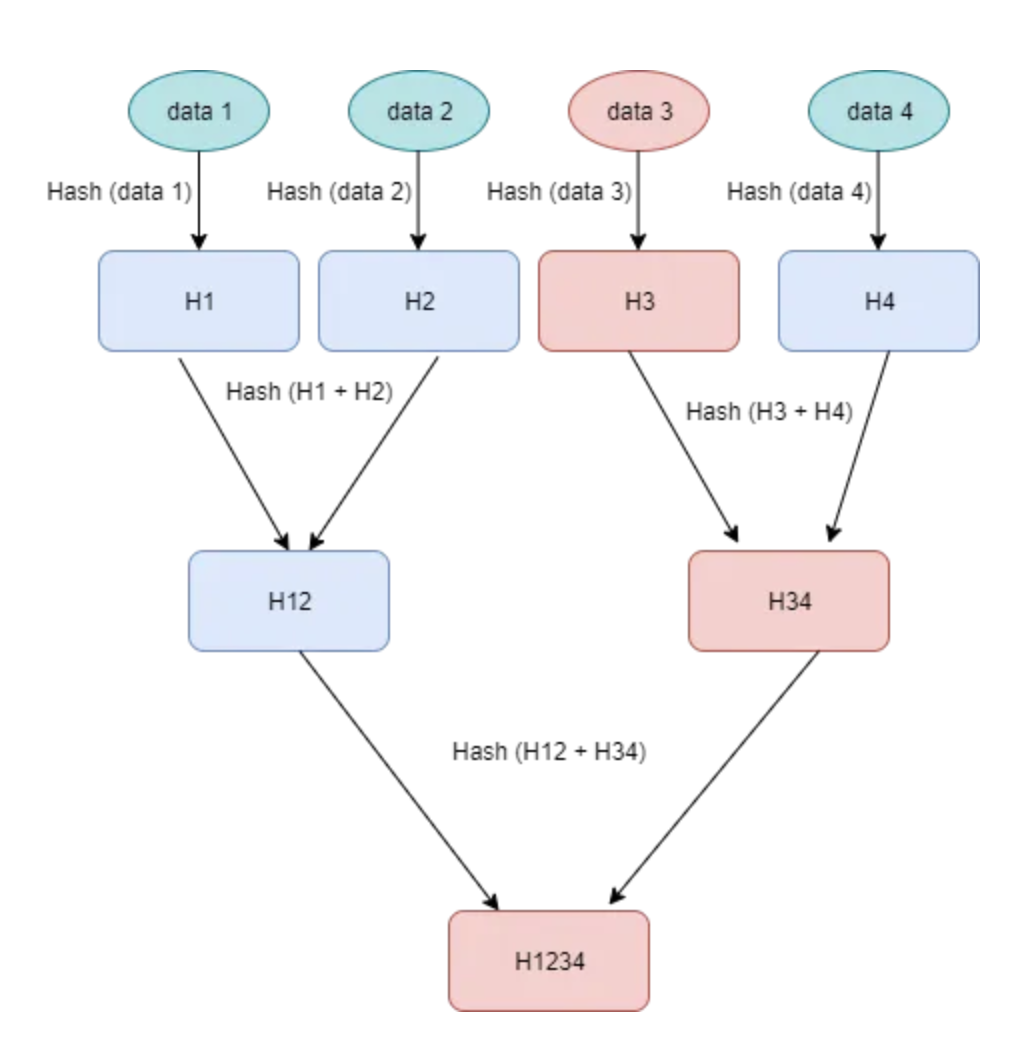
Now on comparing the Merkle Tree of received data to its source. We can see that:
H1234 is different so there are changes. H12 is the same so its sub-tree is clean. Following the hashes that are different, we go from H1234 to H34 to H3 to data3 basically identifying the changed data.
Merkel Tree has been useful in many use cases. DynamoDB uses Merkel Tree for consistent hashing. Git uses Merkel Tree to keep git history. It is also used in internet file sharing. Knowing the root hash from a trusted source we can combine only those data pieces that produce the same root hash allowing us to filter the tempered and infected data pieces.
Originally published on Medium